本文介绍如何使用TextCNN实现恶意程序的分类任务。实验数据来自天池新人赛阿里云安全恶意程序检测 ,整个比赛实现了多种模型,最终通过模型融合实现分类任务,TextCNN为所用模型之一。本文实现了使用torchtext直接从列表加载和处理数据,设计了k-fold cross validation进行交叉验证,并使用torch Conv1d实现textcnn。
通过对原始数据集进行处理之后,训练集和测试集分别用 .plk 文件保存在本地。训练集内容包括特征(恶意程序的API调用序列,每个序列是一个以空格分隔的字符串)和标签,均存储在list中:
import picklewith open('../dataset/security_train.pkl' , 'rb' ) as f: labels = pickle.load(f) train_api = pickle.load(f) print(labels[0 ]) print(train_api[0 ][0 :100 ]) ==============output============== 5 LdrLoadDll LdrGetProcedureAddress LdrGetProcedureAddress...
测试集内容包括文件id(恶意程序)和特征,均存储在list中:
import picklewith open('../dataset/security_test.pkl' , 'rb' ) as f: file_ids = pickle.load(f) test_api = pickle.load(f) print(file_ids[0 ]) print(test_api[0 ][0 :100 ]) ==============output============== 1 RegOpenKeyExA CopyFileA OpenSCManagerA CreateServiceA...
这里我们使用文本处理工具 torchtext 来进行数据的加载和预处理。不同于从 .csv 文件加载数据的常规做法,我们直接从上述列表中加载数据。此外,我们还借助 sklearn 在加载数据过程中实现了对训练集的划分,便于后续的交叉验证。
2.1 加载数据 在 torchtext 中,所有 DataSet 对象中的数据都是一个 examples 列表(可以通过DataSet.examples 获得),而该列表中的每一条数据为一个 example 对象 。因此,我们可以使用 data.Example 中的 fromlist 方法,来从列表中构建数据集。
class MyDataset (object) : def __init__ (self, seed=1234 , test=False) : if torch.cuda.is_available(): print("gpu cuda is available!" ) torch.cuda.manual_seed(seed) else : print("cuda is not available! cpu is available!" ) torch.manual_seed(seed) self.seed = seed self.train_examples = [] self.test_examples = [] self.tokenizer = lambda x: x.split() self.TEXT = data.Field(sequential=True , tokenize=self.tokenizer, fix_length=8000 ) self.LABEL = data.Field(sequential=False , use_vocab=False ) fields = [('file_id' , None ), ('api_seq' , self.TEXT), ('label' , self.LABEL)] if test: with open('../dataset/security_test.pkl' , 'rb' ) as f: file_ids = pickle.load(f) test_api = pickle.load(f) for f_id, tes_api in zip(file_ids, test_api): self.test_examples.append(Example.fromlist([f_id, tes_api, None ], fields)) else : with open('../dataset/security_train.pkl' , 'rb' ) as f: labels = pickle.load(f) train_api = pickle.load(f) for tra_api, label in zip(train_api, labels): self.train_examples.append(Example.fromlist([None , tra_api, label], fields))
对训练集进行划分,便于后的的交叉验证:
def get_fold_data (self, num_folds=5 ) : fields = [('api_seq' , self.TEXT), ('label' , self.LABEL)] kf = KFold(n_splits=num_folds, shuffle=True , random_state=self.seed) train_data_arr = np.array(self.train_examples) for train_index, val_index in kf.split(train_data_arr): yield ( self.TEXT, self.LABEL, data.Dataset(train_data_arr[train_index], fields=fields), data.Dataset(train_data_arr[val_index], fields=fields), ) def get_test_data (self) : return self.test_examples
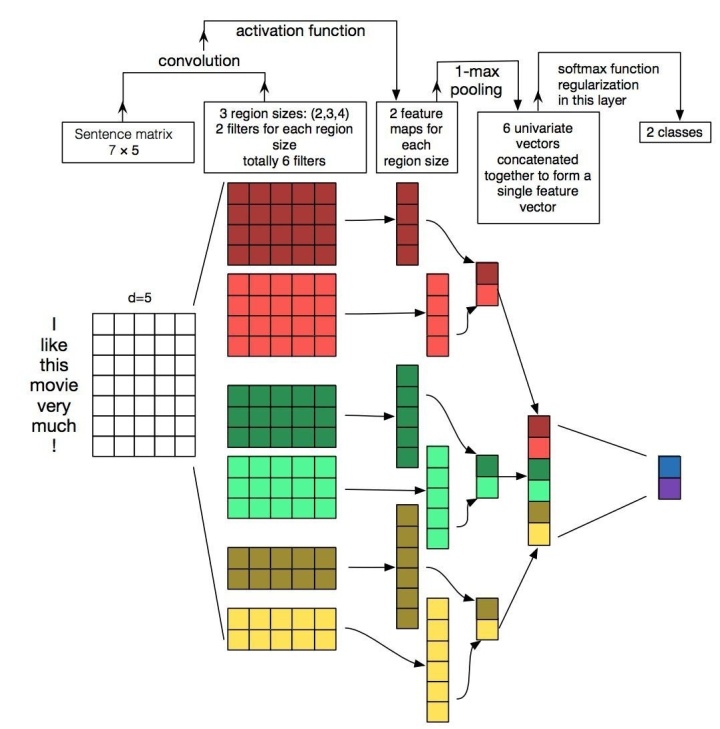
TextCNN模型如下图所示,其过程非常简单。首先对一个 text_len * embedding_size 的矩阵做一维卷积,然后将卷积结果做max pooling后拼接,最后输入到全连接网络中进行分类。
这里我们首先介绍一下torch中Conv1d 和Conv2d :
Conv1d表示卷积的方向是一维的
class torch .nn .Conv1d (in_channels, out_channels, kernel_size, stride=1 , padding=0 , dilation=1 , groups=1 , bias=True) #in_channels (int) 输入信号的通道。在文本分类中,即为词向量的维度;图像中为RGB 三通道。 # out_channels (int) 卷积产生的通道。有多少个out_channels ,就需要多少个1维卷积 # kernel_size (int or tuple) 卷积核的尺寸,卷积核的大小 # stride (int or tuple, optional) 卷积步长 # padding (int or tuple, optional) 输入的每一条边补充0的层数 # dilation (int or tuple, `optional``) 空洞卷积,卷积核元素之间的间距 # groups (int, optional) 从输入通道到输出通道的阻塞连接数 # bias(bool, optional) 如果bias=True,添加偏置
in_channels(int) :输入信号的通道。在文本分类中,即为词向量的维度; out_channels(int) :卷积产生的通道,即filter的数量 kernel_size(int or tuple) : 卷积核的尺寸。kernel_size为int时,其大小kernel_size*in_channels;kernel_size为tuple时,其大小 kernel_size[0]*kernel_size[1] stride(int or tuple, optional) : 卷积步长 padding (int or tuple, optional) :输入的每一条边补充0的层数 dilation(int or tuple, `optional``) :空洞卷积,卷积核元素之间的间距 groups(int, optional) :从输入通道到输出通道的阻塞连接数 bias(bool, optional) : 如果bias=True,添加偏置
class torch .nn .Conv2d (in_channels, out_channels, kernel_size, stride=1 , padding=0 , dilation=1 , groups=1 , bias=True)
Conv2d与Conv1d的参数完全相同,只不过其用在图像卷积中,含义与文本卷积不同。
in_channels :通道数,图像中为RGB三通道。channel本质上定义了一个数据点用几个值来描述 out_channels :同样是filter的数量,也即输出后的通道数 kernel_size :这里的kernel size可以是int或tuple的,如kernel_size=2,那么就是2*2大小的卷积核;如果是(2,3),那么就是一个non-squre的卷积核,相应的stride和padding也可以设置为tuple
所以这里我们可以使用Conv1d和Conv2d实现textcnn。如果使用Conv2d,那么要设置in_channels=1,kernel_size设置为tuple,kernel_size[0]为Conv1d中kernel_size的大小,而kernel_size[1]为Conv1d中in_channels的大小。 (不明白为什么那么多教程用Conv2d实现textcnn)
import torch as thfrom torch import nnfrom torch.nn import Conv2dclass TextCNN (nn.Module) : def __init__ (self) : super(TextCNN, self).__init__() vocab = 304 dim = 256 class_num = 8 filters = 64 kernels = [2 , 3 , 4 , 5 ] dilations = [1 , 2 , 3 , 4 ] self.embed = nn.Embedding(num_embeddings=vocab, embedding_dim=dim) self.dp1 = nn.Dropout2d(0.25 ) self.convs = nn.ModuleList() for ks in kernels: for dila in dilations: self.convs.append(nn.Conv1d(in_channels=dim, out_channels=filters, kernel_size=ks, dilation=dila)) self.conv_ac = nn.ReLU() self.pool1 = nn.AdaptiveMaxPool1d(1 ) self.dp2 = nn.Dropout(0.5 ) self.fc1 = nn.Linear(1024 , 256 ) self.ac1 = nn.ReLU() self.dp3 = nn.Dropout(0.3 ) self.fc2 = nn.Linear(256 , 8 ) def forward (self, x) : x = self.embed(x) x = self.dp1(x) x = x.permute(0 , 2 , 1 ) warppers = [] for conv1d in self.convs: conv = conv1d(x) conv_ac = self.conv_ac(conv) pool = self.pool1(conv_ac) warppers.append(pool.squeeze(-1 )) x = th.cat(warppers, dim=-1 ) x = self.dp2(x) x = self.fc1(x) x = self.ac1(x) x = self.dp3(x) rst = self.fc2(x) return rst
在我们的数据中,假设每个词对应的词向量维度D i m = 256 Dim=256 D i m = 2 5 6 W = 8000 W = 8000 W = 8 0 0 0 N = 32 N=32 N = 3 2
在数据加载时,我们已经实现了分词 ,且无需去除停用词 ,因此我们加载完数据后首先使用TEXT.build_vocab 建立词汇表(词汇表是词语到 index 的映射,index从0到M,M为已知词汇的个数,如{'我‘:0, ‘好’:1, ‘帅’:2…})。
然后我们调用 data.BucketIterator 将产生 Iterator 迭代数据,并指定batch_size,此时Iterator 中每个 batch 的大小即为 batch_size * text_len (32*8000) 。将数据输入到模型中,经过nn.Embedding 层之后,其shape变为 batch_size * text_len * embedding size (32*8000*256),即卷积层的输入 。
由于Torch没有实现cross-validation,因此我们用自定义的data_loader,在训练过程中使用5折交叉验证,即80%的数据训练,20%的数据验证,交叉验证五轮。训练与验证过程的main函数如下:
def main () : data_generator = MyDataset() _history = [] device = None model = None fold_index = 0 for TEXT, LABEL, train_data, val_data in data_generator.get_fold_data(): logger.info("[+] Running Training ..." ) logger.info(f"Now fold: {fold_index + 1 } / {5 } " ) TEXT.build_vocab(train_data) LABEL.build_vocab(train_data) model = TextCNN() optimizer = optim.Adam(model.parameters(), lr=0.00006 , weight_decay=0.00006 ) device = torch.device('cuda:0' ) model = model.to(device) train_iterator = data.BucketIterator(train_data, batch_size=32 , sort_key=lambda x: len(x.api_seq), device=device) val_iterator = data.BucketIterator(val_data, batch_size=32 , sort_key=lambda x: len(x.api_seq), device=device) for epoch in range(80 ): train_loss, train_acc = train_run(model, train_iterator, optimizer, device) val_loss, val_acc = eval_run(model, val_iterator, device) logger.info(f'| Epoch: {epoch + 1 :02 } | Train Loss: {train_loss:.6 f} | Train ACC: {train_acc:.6 f} ' f'| Val Loss: {val_loss:.6 f} | Val ACC: {val_acc:.6 f} ' ) best = model torch.save(model.state_dict(), f"best_model_{fold_index} .pkl" ) fold_index += 1
train_run() 和 eval_run() 会返回训练集和测试集上的loss和accuracy,代码如下:
def train_run (model, iterator, optimizer, device) : epoch_loss = 0 corrects = 0 for batch in iterator: model.train() optimizer.zero_grad() feat = batch.api_seq.t_() output = model(feat) target = batch.label feat, target = feat.to(device), target.to(device) loss = F.cross_entropy(output, target) loss.backward() optimizer.step() epoch_loss += loss.item() result = torch.max(output, 1 )[1 ] corrects += (result.view(target.size()).data == target.data).sum() return epoch_loss / len(iterator), corrects / (len(iterator) * 32 ) def eval_run (model, iterator, device) : epoch_loss = 0 corrects = 0 with torch.no_grad(): for batch in iterator: model.eval() feat = batch.api_seq.t_() predictions = model(feat) target = batch.label feat, target = feat.to(device), target.to(device) loss = F.cross_entropy(predictions, target) epoch_loss += loss.item() result = torch.max(predictions, 1 )[1 ] corrects += (result.view(target.size()).data == target.data).sum() return epoch_loss / len(iterator), corrects / (len(iterator) * 32 )
每次训练结束后,保存最优模型,最后将5个模型在test_data上的输出取平均,即最终结果。
本实验过程仅在测试集数据上做了交叉验证,在真正比赛时,需要在所有数据上构建词典(TEXT.build_vocab(train_data, test_data)),以保证模型在测试集上的精度。
此外,在代码运行过程中,GPU并没有跑满,显存占用8G/10G,GPU利用率80%,内存占满。瓶颈之一是内存不够(16G),另外textcnn的data.BucketIterator不像Dataloader一样可以配置num_workers实现多线程,导致性能没有发挥到最佳。
[1]:TorchText用法示例及完整代码_nlpuser的博客-CSDN博客_torchtext
[2]:pytorch实现textCNN_无所知的博客-CSDN博客
[3]:pytorch TextCNN笔记
[4]:用机器学习进行恶意软件检测–以阿里云恶意软件检测比赛为例 - 先知社区