DGL通过其核心数据结构 DGLGraph 提供了一个以图为中心的编程抽象。 DGLGraph 提供了接口以处理图的结构、节点/边 的特征,以及使用这些组件可以执行的计算。
DGL中图的类型包括:
同构图
异构图
二部图(特殊的异构图)
多重图(同一对节点之间有多条边,包括自循环的边)
DGL使用一个唯一的整数来表示一个节点,称为点ID;并用对应的两个端点ID表示一条边。同时,DGL也会根据边被添加的顺序, 给每条边分配一个唯一的整数编号,称为边ID。节点和边的ID都是从0开始构建的。在DGL的图里,所有的边都是有方向的,即边 (u,v) 表示它是从节点 u 指向节点 v 的。
DGL使用一个一维的整型节点张量来保存图的点ID,使用一个包含2个节点张量的元组 ( U , V ) (U,V) ( U , V ) ( U [ i ] , V [ i ] ) (U[i],V[i]) ( U [ i ] , V [ i ] ) U [ i ] U[i] U [ i ] V [ i ] V[i] V [ i ]
下面的代码段使用了 dgl.graph()DGLGraph
import dglimport torch as thu, v = th.tensor([0 , 0 , 0 , 1 ]), th.tensor([1 , 2 , 3 , 3 ]) g = dgl.graph((u, v)) print(g) ''' Graph(num_nodes=4, num_edges=4, ndata_schemes={} edata_schemes={}) ''' print(g.nodes()) print(g.edges()) print(g.edges(form='all' )) g = dgl.graph((u, v), num_nodes=8 )
创建无向图需要使用dgl.to_bidirected()
bg = dgl.to_bidirected(g) bg.edges()
由于Tensor类内部使用C来存储,且显性定义了数据类型以及存储的设备信息,DGL推荐使用Tensor作为DGL API的输入。 不过大部分的DGL API也支持Python的可迭代类型(比如列表)或numpy.ndarray类型作为API的输入,方便用户快速进行开发验证。
DGL支持使用 32 位或 64 位的整数作为节点ID和边ID。节点和边ID的数据类型必须一致。如果图里的节点或者边的数量小于 2^{63}−1 ,用户最好使用 32 位整数。 这样不仅能提升速度,还能减少内存的使用。DGL提供了进行数据类型转换的方法,如下例所示:
edges = th.tensor([2 , 5 , 3 ]), th.tensor([3 , 5 , 0 ]) g64 = dgl.graph(edges) g32 = dgl.graph(edges, idtype=th.int32) g64_2 = g32.long() g32_2 = g64.int()
DGLGraphndataedata
import dglimport torch as thg = dgl.graph(([0 , 0 , 1 , 5 ], [1 , 2 , 2 , 0 ])) g.ndata['x' ] = th.ones(g.num_nodes(), 3 ) g.edata['x' ] = th.ones(g.num_edges(), dtype=th.int32) ''' Graph(num_nodes=6, num_edges=4, ndata_schemes={'x' : Scheme(shape=(3,), dtype=torch.float32)} edata_schemes={'x' : Scheme(shape=(,), dtype=torch.int32)}) ''' g.ndata['y' ] = th.randn(g.num_nodes(), 5 ) g.ndata['x' ][1 ] g.edata['x' ][th.tensor([0 , 3 ])]
关于 ndata 和 edata 接口的重要说明:
仅允许使用数值类型 (如单精度浮点型、双精度浮点型和整型)的特征。这些特征可以是标量、向量或多维张量。每个节点特征具有唯一名称,每个边特征也具有唯一名称。节点和边的特征可以具有相同的名称(如上述示例代码中的 'x' )。
通过张量分配创建特征时,DGL会将特征赋给图中的每个节点和每条边。该张量的第一维必须与图中节点或边的数量一致。 不能将特征赋给图中节点或边的子集。
相同名称的特征必须具有相同的维度和数据类型。
特征张量使用”行优先”的原则,即每个行切片储存1个节点或1条边的特征 。
对于加权图,用户可以将权重储存为一个边特征:
edges = th.tensor([0 , 0 , 0 , 1 ]), th.tensor([1 , 2 , 3 , 3 ]) weights = th.tensor([0.1 , 0.6 , 0.9 , 0.7 ]) g = dgl.graph(edges) g.edata['w' ] = weights
可以从外部来源构造一个 DGLGraph
以下代码片段为从 SciPy 稀疏矩阵和 NetworkX 图创建 DGL 图的示例:
import dglimport torch as thimport scipy.sparse as spspmat = sp.rand(100 , 100 , density=0.05 ) dgl.from_scipy(spmat) ''' num_edges = 0.05*100*100 Graph(num_nodes=100, num_edges=500, ndata_schemes={} edata_schemes={}) ''' import networkx as nxnx_g = nx.path_graph(5 ) dgl.from_networkx(nx_g) ''' Graph(num_nodes=5, num_edges=8, ndata_schemes={} edata_schemes={}) '''
注意,当使用 nx.path_graph(5) 进行创建时, DGLGraphnetworkx.GraphDGLGraphDGLGraphnetworkx.DiGraph
相关API: dgl.save_graphs()dgl.load_graphs()
dgl.save_graphs(filename, g_list, labels=None)
filename (str g_list (list labels (dict [ str , Tensor]) – labels should be dict of tensors, with str as keys
from dgl.data.utils import save_graphsgraph_labels = {"glabel" : th.tensor([0 , 1 ])} save_graphs("./data.bin" , [g1, g2], graph_labels)
dgl.load_graphs(filename, idx_list=None)
Parameters
filename (str) – The file name to load graphs from.idx_list (list[int], optional) – The indices of the graphs to be loaded if the file contains multiple graphs. Default is loading all the graphs stored in the file.
Returns
graph_list (list[DGLGraph]) – The loaded graphs.labels (dict[str, Tensor]) – The graph labels stored in file. If no label is stored, the dictionary is empty. Regardless of whether the idx_list argument is given or not, the returned dictionary always contains the labels of all the graphs.
from dgl.data.utils import load_graphsglist, label_dict = load_graphs("./data.bin" ) glist, label_dict = load_graphs("./data.bin" , [0 ])
异构图中不同类型的节点和边具有独立的 ID空间和特征。在DGL中,一个异构图由一系列子图构成,一个子图对应一种关系。每个关系由一个字符串三元组 定义 (源节点类型, 边类型, 目标节点类型) 。
import dglimport torch as thgraph_data = { ('drug' , 'interacts' , 'drug' ): (th.tensor([0 , 1 ]), th.tensor([1 , 2 ])), ('drug' , 'interacts' , 'gene' ): (th.tensor([0 , 1 ]), th.tensor([2 , 3 ])), ('drug' , 'treats' , 'disease' ): (th.tensor([1 ]), th.tensor([2 ])) } g = dgl.heterograph(graph_data) g.ntypes g.etypes g.canonical_etypes ''' [('drug', 'interacts', 'drug'), ('drug', 'interacts', 'gene'), ('drug', 'treats', 'disease')] '''
与异构图相关联的 metagraph 就是图的模式。它指定节点集和节点之间的边的类型约束。 metagraph 中的一个节点 u 对应于相关异构图中的一个节点类型。 metagraph 中的边 (u,v) 表示在相关异构图中存在从 u 型节点到 v 型节点的边。
g ''' Graph(num_nodes={'disease': 3, 'drug': 3, 'gene': 4}, num_edges={('drug', 'interacts', 'drug'): 2, ('drug', 'interacts', 'gene'): 2, ('drug', 'treats', 'disease'): 1}, metagraph=[('drug', 'drug', 'interacts'), ('drug', 'gene', 'interacts'), ('drug', 'disease', 'treats')]) ''' g.metagraph().edges() ''' OutMultiEdgeDataView([('drug', 'drug'), ('drug', 'gene'), ('drug', 'disease')]) ''' g.metagraph().nodes()
g.num_nodes() g.num_nodes('drug' ) g.nodes() g.nodes('drug' )
设置/获取特定节点和边类型的特征 :
g.nodes[‘node_type’].data[‘feat_name’]
g.edges[‘edge_type’].data[‘feat_name’]
g.nodes['drug' ].data['hv' ] = th.ones(3 , 1 ) g.nodes['drug' ].data['hv' ] g.edges['treats' ].data['he' ] = th.zeros(1 , 1 ) g.edges['treats' ].data['he' ]
如果图里只有一种节点或边类型,则不需要指定节点或边的类型。
g = dgl.heterograph({ ('drug' , 'interacts' , 'drug' ): (th.tensor([0 , 1 ]), th.tensor([1 , 2 ])), ('drug' , 'is similar' , 'drug' ): (th.tensor([0 , 1 ]), th.tensor([2 , 3 ])) }) g.nodes() g.ndata['hv' ] = th.ones(4 , 1 )
当边类型唯一地确定了源节点和目标节点的类型时,用户可以只使用一个字符串而不是字符串三元组来指定边类型。例如, 对于具有两个关系 ('user', 'plays', 'game') 和 ('user', 'likes', 'game') 的异构图, 只使用 'plays' 或 'like' 来指代这两个关系是可以的。否则,需要使用三元组指定
用户可以通过指定要保留的关系来创建异构图的子图 ,相关的特征也会被拷贝。
g = dgl.heterograph({ ('drug' , 'interacts' , 'drug' ): (th.tensor([0 , 1 ]), th.tensor([1 , 2 ])), ('drug' , 'interacts' , 'gene' ): (th.tensor([0 , 1 ]), th.tensor([2 , 3 ])), ('drug' , 'treats' , 'disease' ): (th.tensor([1 ]), th.tensor([2 ])) }) g.nodes['drug' ].data['hv' ] = th.ones(3 , 1 ) eg = dgl.edge_type_subgraph(g, [('drug' , 'interacts' , 'drug' ), ('drug' , 'treats' , 'disease' )]) eg eg.nodes['drug' ].data['hv' ]
DGL允许使用 dgl.DGLGraph.to_homogeneous() API将异构图转换为同构图:
1. 用从0开始的连续整数重新标记所有类型的节点和边。
2. 对所有的节点和边合并用户指定的特征。
g = dgl.heterograph({ ('drug' , 'interacts' , 'drug' ): (th.tensor([0 , 1 ]), th.tensor([1 , 2 ])), ('drug' , 'treats' , 'disease' ): (th.tensor([1 ]), th.tensor([2 ]))}) g.nodes['drug' ].data['hv' ] = th.zeros(3 , 1 ) g.nodes['disease' ].data['hv' ] = th.ones(3 , 1 ) g.edges['interacts' ].data['he' ] = th.zeros(2 , 1 ) g.edges['treats' ].data['he' ] = th.zeros(1 , 2 ) hg = dgl.to_homogeneous(g) 'hv' in hg.ndatahg = dgl.to_homogeneous(g, edata=['he' ]) hg = dgl.to_homogeneous(g, ndata=['hv' ]) hg.ndata['hv' ] ''' tensor([[1.], [1.], [1.], [0.], [0.], [0.]]) '''
原始的节点或边的类型和对应的ID被存储在 ndataedata
g.ntypes hg.ndata[dgl.NTYPE] hg.ndata[dgl.NID] g.etypes hg.edata[dgl.ETYPE] hg.edata[dgl.EID]
出于建模的目的,用户可能需要将一些关系合并,并对它们应用相同的操作。为了实现这一目的,可以先抽取异构图的边类型子图,然后将该子图转换为同构图 。
g = dgl.heterograph({ ('drug' , 'interacts' , 'drug' ): (th.tensor([0 , 1 ]), th.tensor([1 , 2 ])), ('drug' , 'interacts' , 'gene' ): (th.tensor([0 , 1 ]), th.tensor([2 , 3 ])), ('drug' , 'treats' , 'disease' ): (th.tensor([1 ]), th.tensor([2 ])) }) sub_g = dgl.edge_type_subgraph(g, [('drug' , 'interacts' , 'drug' ), ('drug' , 'interacts' , 'gene' )]) h_sub_g = dgl.to_homogeneous(sub_g) h_sub_g
用户可以通过在构造过程中传入两个GPU张量来创建GPU上的 DGLGraphto()DGLGraph
import dglimport torch as thu, v = th.tensor([0 , 1 , 2 ]), th.tensor([2 , 3 , 4 ]) g = dgl.graph((u, v)) g.ndata['x' ] = th.randn(5 , 3 ) g.device cuda_g = g.to('cuda:0' ) cuda_g.device cuda_g.ndata['x' ].device u, v = u.to('cuda:0' ), v.to('cuda:0' ) g = dgl.graph((u, v)) g.device
任何涉及GPU图的操作都是在GPU上运行的。因此,这要求所有张量参数都已经放在GPU上,其结果(图或张量)也将在GPU上。 此外,GPU图只接受GPU上的特征数据。
cuda_g.in_degrees() cuda_g.in_edges([2 , 3 , 4 ]) cuda_g.in_edges(th.tensor([2 , 3 , 4 ]).to('cuda:0' )) cuda_g.ndata['h' ] = th.randn(5 , 4 )
消息传递是Deep Graph Library (DGL) 实现GNN的一种通用框架和编程范式。它从聚合与更新的角度归纳总结了多种GNN模型的实现。假设节点 v 上的特征为x v x_v x v w e w_e w e
Edge-wise: m e ( t + 1 ) = ϕ ( x v ( t ) , x u ( t ) , w e ( t ) ) , ( u , v , e ) ∈ E \text{Edge-wise: } m_{e}^{(t+1)} = \phi \left( x_v^{(t)}, x_u^{(t)}, w_{e}^{(t)} \right) , ({u}, {v},{e}) \in \mathcal{E}
Edge-wise: m e ( t + 1 ) = ϕ ( x v ( t ) , x u ( t ) , w e ( t ) ) , ( u , v , e ) ∈ E
Node-wise: x v ( t + 1 ) = ψ ( x v ( t ) , ρ ( { m e ( t + 1 ) : ( u , v , e ) ∈ E } ) ) \text{Node-wise: } x_v^{(t+1)} = \psi \left(x_v^{(t)}, \rho\left(\left\lbrace m_{e}^{(t+1)} : ({u}, {v},{e}) \in \mathcal{E} \right\rbrace \right) \right)
Node-wise: x v ( t + 1 ) = ψ ( x v ( t ) , ρ ( { m e ( t + 1 ) : ( u , v , e ) ∈ E } ) )
消息函数 (Message Function) ϕ \phi ϕ
聚合函数 (Reduce Function) ρ \rho ρ
更新函数 (Update Function) ψ \psi ψ
DGL在命名空间 dgl.function 中实现了常用的消息函数和聚合函数作为 内置函数 尽可能 使用内置函数,因为它们经过了大量优化,并且可以自动处理维度广播。
在DGL中,消息函数 接受一个参数 edges,这是一个 EdgeBatch 的实例, 在消息传递时,它被DGL在内部生成以表示一批边。 edges 有 src、 dst 和 data 共3个成员属性, 分别用于访问源节点、目标节点和边的特征。
消息的内置函数的命名约定是 u 表示 源 节点, v 表示 目标 节点,e 表示 边。例如,要对源节点的 hu 特征和目标节点的 hv 特征求和, 然后将结果保存在边的 he 特征上,用户可以使用内置函数dgl.function.u_add_v('hu', 'hv', 'he')。
接受一个参数 nodes,这是一个 NodeBatch 的实例, 在消息传递时,它被DGL在内部生成以表示一批节点。 nodes 的成员属性 mailbox 可以用来访问节点收到的消息。 一些最常见的聚合操作包括 sum、max、min 等。
DGL支持内置的聚合函数 sum、 max、 min 和 mean 操作。 聚合函数通常有两个参数,它们的类型都是字符串。一个用于指定 mailbox 中的字段名,一个用于指示目标节点特征的字段名, 例如, dgl.function.sum('m', 'h')
接受一个如上所述的参数 nodes。此函数对 聚合函数 的聚合结果进行操作, 通常在消息传递的最后一步将其与节点的特征相结合,并将输出作为节点的新特征。
import dglimport torch as thimport dgl.function as fndef message_func (edges) : return {'m' : edges.src['feat' ] + edges.dst['feat' ]} def reduce_func (nodes) : return {'h' : th.sum(nodes.mailbox['m' ], dim=1 )} def updata_all_example (graph) : graph.update_all(fn.u_mul_e('feat' , 'a' , 'm' ), fn.sum('m' , 'feat' )) final_ft = graph.ndata['feat' ] * 2 graph.ndata['feat' ] = final_ft return graph if __name__ == '__main__' : u, v = th.tensor([0 ,1 ,2 ,3 ]), th.tensor([1 ,2 ,3 ,4 ]) g = dgl.graph((u,v)) g.ndata['feat' ] = th.ones(5 , 2 ) fn.u_add_v('feat' , 'feat' , 'm' ) fn.sum('m' , 'h' ) g.update_all(fn.u_add_v('feat' , 'feat' , 'm' ), fn.sum('m' , 'h' )) g.apply_edges(fn.u_add_v('feat' , 'feat' , 'a' )) g2 = dgl.graph((u,v)) g2.ndata['feat' ] = th.ones(5 , 2 ) g2.edata['a' ] = th.ones(4 , 2 ) updated_g2 = updata_all_example(g2) print(g2.ndata) ''' output: {'feat': tensor([[0., 0.], [2., 2.], [2., 2.], [2., 2.], [2., 2.]])} ''' g3 = dgl.graph((u,v)) g3.ndata['feat' ] = th.ones(5 , 2 ) g3.update_all(message_func, reduce_func) print(g3.ndata) ''' output: {'feat': tensor([[0., 0.], [2., 2.], [2., 2.], [2., 2.], [2., 2.]])} '''
DGL建议用户尽量减少边 的特征维数。下面是一个如何通过对节点特征降维来减少消息维度 的示例。该做法执行以下操作:拼接 源 节点和 目标 节点特征(按照dim=-1拼接,n不变),然后应用一个线性层,即 W × ( u ∣ ∣ v ) W\times (u || v) W × ( u ∣ ∣ v ) 源 节点和 目标 节点特征维数较高,而线性层输出维数较低。
import dglimport torch as thimport torch.nn as nnimport dgl.function as fngraph = dgl.rand_graph(5 , 6 ) graph.ndata['feat' ] = th.ones(5 , 8 ) in_dim = 8 out_dim = 3 w_l = nn.Parameter(th.FloatTensor(size=(in_dim, out_dim))) w_r = nn.Parameter(th.FloatTensor(size=(in_dim, out_dim))) w = th.cat([w_l, w_r], 0 ) def concat (edges) : return {'h' : th.cat([edges.src['feat' ], edges.dst['feat' ]], -1 )} graph.apply_edges(concat) graph.edata['e' ] = graph.edata['h' ] @ w print(graph.edata['e' ]) graph.srcdata['h_src' ] = graph.ndata['feat' ] @ w_l graph.dstdata['h_dst' ] = graph.ndata['feat' ] @ w_r graph.apply_edges(fn.u_add_v('h_src' , 'h_dst' , 'e' )) print(graph.edata['e' ])
其中,第二种方法将线性操作分成两部分,一个应用于 源 节点特征,另一个应用于 目标 节点特征。 在最后一个阶段,在边上将以上两部分线性操作的结果相加,即执行 W l × u + W r × v W_l\times u + W_r \times v W l × u + W r × v W × ( u ∣ ∣ v ) = ( W l × u ) ∣ ∣ ( W r × v ) W \times (u||v) = (W_l \times u) || (W_r \times v) W × ( u ∣ ∣ v ) = ( W l × u ) ∣ ∣ ( W r × v ) w l w_l w l w r w_r w r W W W
以上两个实现在数学上是等价的。后一种方法效率高得多,因为不需要在边上保存concatenate之后的结果(前面说过DGL在边上保存信息是十分消耗内存的), 从内存角度来说是高效的。另外,加法可以通过DGL的内置函数 u_add_v 进行优化,从而进一步加快计算速度并节省内存占用。
总之,该示例是为了说明在编写DGL模型时,应注意尽量不要在边上保存信息,尽量使用内置函数。
[注] 关于g.srcdata[‘feat’]和g.dstdata[‘feat’]:
在异构图中,g.srcdata[‘feat’] 可以表示单种或多种源节点的feature;g.dstdata[‘feat’]同理
而在同构图中,g.srcdata[‘feat’] 和g.dstdata[‘feat’] 均表示所有节点的feature
如果用户只想更新图中的部分节点,可以先通过想要囊括的节点编号创建一个子图, 然后在子图上调用 update_all()
nid = [0 , 2 , 3 , 6 , 7 , 9 ] sg = g.subgraph(nid) sg.update_all(message_func, reduce_func) apply_node_func()
一类常见的图神经网络建模的做法是在消息聚合前使用边的权重, 比如在 图注意力网络(GAT) 和一些 GCN的变种 。DGL的处理方法是:
将权重存为边的特征。
在消息函数中用边的特征与源节点的特征相乘。
例如:
import dgl.function as fngraph.edata['a' ] = th.tensor([1 ,2 ,3 ,4 ,5 ]) graph.update_all(fn.u_mul_e('ft' , 'a' , 'm' ), fn.sum('m' , 'ft' ))
异构图上的消息传递可以分为两个部分:
(1)对每个关系计算和聚合消息。
(2)对每个结点聚合来自不同关系的消息。
在DGL中,对异构图进行消息传递的接口是 multi_update_all()multi_update_all()update_all()multi_update_all()sum、 min、 max、 mean 和 stack 中的一个。以下是一个例子:
import dgl.function as fng = dgl.heterograph({('user' , 'follows' , 'user' ): (th.tensor([0 , 1 ]), th.tensor([1 , 2 ])), ('user' , 'follows' , 'game' ): (th.tensor([0 , 1 , 2 ]), th.tensor([1 , 2 , 3 ])), ('user' , 'plays' , 'game' ): (th.tensor([1 , 3 ]), th.tensor([2 , 3 ])) }) funcs = {} g.srcdata['feat' ]={'user' : th.ones(4 , 1 ), 'game' : th.ones(4 , 1 )} for c_etype in g.canonical_etypes: srctype, etype, dsttype = c_etype funcs[c_etype] = (fn.copy_u('feat' , 'm' ), fn.mean('m' , 'h' )) g.multi_update_all(funcs, 'sum' ) print(g.ndata) ''' {'game': {'feat': tensor([[1.], [1.], [1.], [1.]]), 'h': tensor([[0.], [1.], [2.], [2.]])}, 'user': {'feat': tensor([[1.], [1.], [1.], [1.]]), 'h': tensor([[0.], [1.], [1.], [0.]])} } '''
import torch.nn as nn
构造函数完成以下几个任务:
设置选项:构造函数参数的设置
注册可学习的参数或者子模块:模块是纯 PyTorch NN 模块,例如 nn.Linear、 nn.LSTM 等
初始化参数:调用 reset_parameters() 进行权重初始化
在NN模块中, forward() 函数执行了实际的消息传递和计算。与通常以张量为参数的PyTorch NN模块相比, DGL NN模块额外增加了1个参数 dgl.DGLGraphforward() 函数的内容一般可以分为3项操作:
检测输入图对象是否符合规范。
消息传递和聚合:message function & reduce function
聚合后,更新特征作为输出。
forward() 函数需要处理输入的许多极端情况,这些情况可能导致计算和消息传递中的值无效。 比如在 GraphConvmailbox 将为空,并且聚合函数的输出值全为0, 这可能会导致模型性能不佳。但是,在 SAGEConvforward() 函数的输出不会全为0。在这种情况下,无需进行此类检验。
DGL提供了 HeteroGraphConvmulti_update_all()
每个关系上的DGL NN模块。
聚合来自不同关系上的结果。
其数学定义为:
h d s t ( l + 1 ) = A G G r ∈ R , r d s t = d s t ( f r ( g r , h r s r c l , h r d s t l ) ) h_{dst}^{(l+1)} = \underset{r\in\mathcal{R}, r_{dst}=dst}{AGG} (f_r(g_r, h_{r_{src}}^l, h_{r_{dst}}^l))
h d s t ( l + 1 ) = r ∈ R , r d s t = d s t A GG ( f r ( g r , h r s r c l , h r d s t l ) )
其中 f r f_r f r
import torch.nn as nnclass HeteroGraphConv (nn.Module) : def __init__ (self, mods, aggregate='sum' ) : super(HeteroGraphConv, self).__init__() self.mods = nn.ModuleDict(mods) if isinstance(aggregate, str): self.agg_fn = get_aggregate_fn(aggregate) else : self.agg_fn = aggregate
异构图的卷积操作接受一个字典类型参数 mods。这个字典的键为关系名,值为作用在该关系上NN模块对象。参数 aggregate 则指定了如何聚合来自不同关系 的结果。
def forward (self, g, inputs, mod_args=None, mod_kwargs=None) : ''' inputs : dict[str, Tensor] or pair of dict[str, Tensor] Input node features. mod_args : dict[str, tuple[any]], optional Extra positional arguments for the sub-modules. mod_kwargs : dict[str, dict[str, any]], optional Extra key-word arguments for the sub-modules. ''' if mod_args is None : mod_args = {} if mod_kwargs is None : mod_kwargs = {} outputs = {nty : [] for nty in g.dsttypes}
除了输入图和输入特征张量,forward() 函数还使用2个额外的字典参数 mod_args 和 mod_kwargs。 这2个字典与 self.mods 具有相同的键,值则为对应 NN 模块的自定义参数。
forward() 函数的输出结果也是一个字典类型的对象。其键为 nty,其值为每个目标节点类型 nty 的输出张量的列表, 表示来自不同关系的计算结果。HeteroGraphConv 会对这个列表进一步聚合,并将结果返回给用户。
if g.is_block: src_inputs = inputs dst_inputs = {k: v[:g.number_of_dst_nodes(k)] for k, v in inputs.items()} else : src_inputs = dst_inputs = inputs for stype, etype, dtype in g.canonical_etypes: rel_graph = g[stype, etype, dtype] if rel_graph.num_edges() == 0 : continue if stype not in src_inputs or dtype not in dst_inputs: continue dstdata = self.mods[etype]( rel_graph, (src_inputs[stype], dst_inputs[dtype]), *mod_args.get(etype, ()), **mod_kwargs.get(etype, {})) outputs[dtype].append(dstdata)
输入 g 可以是异构图或来自异构图的子图区块。和普通的NN模块一样,forward() 函数需要分别处理不同的输入图类型
上述代码中的for循环为处理异构图计算的主要逻辑。首先我们遍历图中所有的关系(通过调用 canonical_etypes)。 通过关系名,我们可以使用 g[ stype, etype, dtype ] 的语法将只包含该关系的子图 ( rel_graph ) 抽取出来。 对于二分图,输入特征将被组织为元组 (src_inputs[stype], dst_inputs[dtype])。 接着调用用户预先注册在该关系上的NN模块,并将结果保存在outputs字典中。
rsts = {} for nty, alist in outputs.items(): if len(alist) != 0 : rsts[nty] = self.agg_fn(alist, nty)
最后,HeteroGraphConv 会调用用户注册的 self.agg_fn 函数聚合来自多个关系的结果。
DGL在 dgl.data 里实现了很多常用的图数据集。它们遵循了由 dgl.data.DGLDatasetdgl.data.DGLDataset
DGLDatasetdgl.data 中定义的图数据集的基类。 它实现了用于处理图数据的基本模版。下面的流程图展示了这个模版的工作方式。
为了处理位于远程服务器或本地磁盘上的图数据集,下面的例子中定义了一个类,称为 MyDataset, 它继承自 dgl.data.DGLDataset
from dgl.data import DGLDatasetclass MyDataset (DGLDataset) : """ 用于在DGL中自定义图数据集的模板: Parameters ---------- url : str 下载原始数据集的url。 raw_dir : str 指定下载数据的存储目录或已下载数据的存储目录。默认: ~/.dgl/ save_dir : str 处理完成的数据集的保存目录。默认:raw_dir指定的值 force_reload : bool 是否重新导入数据集。默认:False verbose : bool 是否打印进度信息。 """ def __init__ (self, url=None, raw_dir=None, save_dir=None, force_reload=False, verbose=False) : super(MyDataset, self).__init__(name='dataset_name' , url=url, raw_dir=raw_dir, save_dir=save_dir, force_reload=force_reload, verbose=verbose) def download (self) : pass def process (self) : pass def __getitem__ (self, idx) : pass def __len__ (self) : pass def save (self) : pass def load (self) : pass def has_cache (self) : pass
DGLDatasetprocess(), __getitem__(idx) 和 __len__()。子类必须实现这些函数。同时DGL也建议实现保存和导入函数, 因为对于处理后的大型数据集,这么做可以节省大量的时间, 并且有多个已有的API可以简化此操作(请参阅 4.4 保存和加载数据 )。
请注意, DGLDatasetDGLDataset
如果用户有包含数百万甚至数十亿个节点或边的大图,通常无法进行 第5章:训练图神经网络 中所述的全图训练。考虑在一个有 NN 个节点的图上运行的、隐层大小为 HH 的 LL 层图卷积网络, 存储隐层表示需要 O(NLH)O(NLH) 的内存空间,当 NN 较大时,这很容易超过一块GPU的显存限制。
本章介绍了一种在大图上进行随机小批次训练的方法,可以让用户不用一次性把所有节点特征拷贝到GPU上。
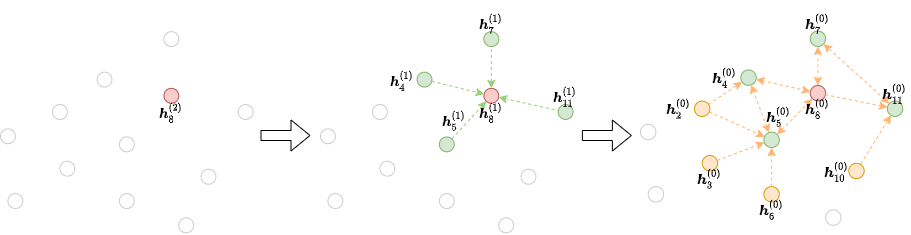
邻居节点采样的工作流程通常如下:每次梯度下降,选择一批mini-batch的图节点, 其最终表示将在神经网络的第 L 层进行计算,然后在网络的第 L−1 层选择该批次节点的全部或部分邻居节点(采样邻居数量)。 重复这个过程,直到到达输入层。这个迭代过程会构建计算的依赖关系图,从输出开始,一直到输入,如下图所示:
该方法能节省在大图上训练图神经网络的开销和计算资源。
DGL实现了一些邻居节点采样的方法和使用邻居节点采样训练图神经网络的管道,同时也支持让用户自定义采样策略。
为了随机(批次)训练模型,需要进行以下操作:
定义邻居采样器。
调整模型以进行小批次训练。
修改模型训练循环部分。
DGL提供了几个邻居采样类,这些类会生成需计算的节点在每一层计算时所需的依赖图。
最简单的邻居采样器是 MultiLayerFullNeighborSampler所有邻居 。完整的内置采样方法清单,可以参考 neighborhood sampler API reference 。
DGL中分batch训练,主要用到的是dgl.dataloading包,且目前只支持了pytorch版的框架中,它主要有两个dataloader类:dgl.dataloading.pytorch.NodeDataLoader和dgl.dataloading.pytorch.EdgeDataLoader。前者一般用于节点分类任务,后者用于边预测任务。
例如,以下代码创建了一个PyTorch的 DataLoader,它分批迭代训练节点ID数组 train_nids。
import dglimport dgl.nn as dglnnimport torchimport torch.nn as nnimport torch.nn.functional as Fsampler = dgl.dataloading.MultiLayerFullNeighborSampler(2 ) dataloader = dgl.dataloading.NodeDataLoader( g, train_nids, sampler, batch_size=1024 , shuffle=True , drop_last=False , num_workers=4 )
NodeDataLoader比较常规的几个参数有:
g:数据图 nids:输入模型的节点id block_sampler:预先定义的采样器,如dgl.dataloading.MultiLayerNeighborSampler([15, 10, 5]) 表示第一层为每个节点采样15个邻居,第二层采样10个邻居,第三层采样5个邻居 剩下的其它参数,就与pytorch中dataloader的参数相似了 例如 batch_size:设置一个数字是每个batch中的节点数目 shuffle:是否打乱顺序 ...
接下来我们写个demo,看一下对DataLoader迭代的结果:
g = dgl.rand_graph(20 ,50 ) train_id = g.nodes() sampler = dgl.dataloading.MultiLayerNeighborSampler([2 ,3 ,4 ]) dataloader = dgl.dataloading.NodeDataLoader( g, train_id, sampler, batch_size=5 ) input_nodes, output_nodes, blocks = next(iter(dataloader)) print(input_nodes) print(output_nodes) print(blocks) ''' tensor([ 0, 1, 2, 3, 4, 16, 6, 18, 10, 11, 5, 13, 17, 15, 14, 9, 7]) tensor([0, 1, 2, 3, 4]) [Block(num_src_nodes=17, num_dst_nodes=17, num_edges=31), Block(num_src_nodes=17, num_dst_nodes=11, num_edges=27), Block(num_src_nodes=11, num_dst_nodes=5, num_edges=13)] '''
对 DataLoader 进行迭代,会返回三个参数:
input_nodes:在当前batch中用到的所有的节点id
output_nodes:当前batch选定的节点id
blocks:block列表,表示每层的计算依赖;如Block(num_src_nodes=11, num_dst_nodes=5, num_edges=13)表示第三层依赖关系图要embedding的节点数为5(batch_size),每个节点sample邻居数为4,由此得到该block的属性。
在git上的例子中,一般都用的到下面两行代码,分别取出输入节点的特征向量,以及在这个batch中输出节点的label
input_feas = blocks[0 ].srcdata['feas' ] output_label = blocks[-1 ].dstdata['label' ]
如果用户的消息传递模块全使用的是DGL内置模块,则模型在进行小批次训练时只需做很小的调整。 以多层GCN为例。如果用户模型在全图上是按以下方式实现的:
class TwoLayerGCN (nn.Module) : def __init__ (self, in_features, hidden_features, out_features) : super().__init__() self.conv1 = dglnn.GraphConv(in_features, hidden_features) self.conv2 = dglnn.GraphConv(hidden_features, out_features) def forward (self, g, x) : x = F.relu(self.conv1(g, x)) x = F.relu(self.conv2(g, x)) return x
然后,我们所需要做的就是用上面生成的块( block )来替换图( g ):
class StochasticTwoLayerGCN (nn.Module) : def __init__ (self, in_features, hidden_features, out_features) : super().__init__() self.conv1 = dgl.nn.GraphConv(in_features, hidden_features) self.conv2 = dgl.nn.GraphConv(hidden_features, out_features) def forward (self, blocks, x) : x = F.relu(self.conv1(blocks[0 ], x)) x = F.relu(self.conv2(blocks[1 ], x)) return x
这里的模型的训练循环仅包含使用定制的批处理迭代器遍历数据集的内容。在每个生成块列表的迭代中:
将与输入节点相对应的节点特征 加载到GPU上。节点特征可以存储在内存或外部存储中。 请注意,用户只需要加载输入节点的特征 ,而不是像整图训练那样加载所有节点的特征。
如果特征存储在 g.ndata 中,则可以通过 blocks[0].srcdata 来加载第一个块的输入节点的特征, 这些节点是计算节点最终表示所需的所有必需的节点。
将块列表和输入节点特征传入多层GNN并获取输出。
将与输出节点相对应的节点标签加载到GPU上。同样,节点标签可以存储在内存或外部存储器中。 再次提醒下,用户只需要加载输出节点的标签,而不是像整图训练那样加载所有节点的标签。
如果特征存储在 g.ndata 中,则可以通过访问 blocks[-1].dstdata 中的特征来加载标签, 它是最后一个块的输出节点的特征,这些节点与用户希望计算最终表示的节点相同。
计算损失并反向传播。
model = StochasticTwoLayerGCN(in_features, hidden_features, out_features) model = model.cuda() opt = torch.optim.Adam(model.parameters()) for input_nodes, output_nodes, blocks in dataloader: blocks = [b.to(torch.device('cuda' )) for b in blocks] input_features = blocks[0 ].srcdata['features' ] output_labels = blocks[-1 ].dstdata['label' ] output_predictions = model(blocks, input_features) loss = compute_loss(output_labels, output_predictions) opt.zero_grad() loss.backward() opt.step()
DGL提供了一个端到端的随机批次训练示例 GraphSAGE的实现 。
在异构图上训练图神经网络进行节点分类的方法也是类似的。
例如,在 异构图上的节点分类模型的训练 中介绍了如何在整图上训练一个2层的RGCN模型。 RGCN小批次训练的代码与它非常相似(为简单起见,这里删除了自环、非线性和基分解)
class StochasticTwoLayerRGCN (nn.Module) : def __init__ (self, in_feat, hidden_feat, out_feat, rel_names) : super().__init__() self.conv1 = dglnn.HeteroGraphConv({ rel : dglnn.GraphConv(in_feat, hidden_feat, norm='right' ) for rel in rel_names }) self.conv2 = dglnn.HeteroGraphConv({ rel : dglnn.GraphConv(hidden_feat, out_feat, norm='right' ) for rel in rel_names }) def forward (self, blocks, x) : x = self.conv1(blocks[0 ], x) x = self.conv2(blocks[1 ], x) return x
DGL提供的一些采样方法也支持异构图。例如,用户仍然可以使用 MultiLayerFullNeighborSamplerNodeDataLoader为训练集指定节点类型和节点ID的字典 。
sampler = dgl.dataloading.MultiLayerFullNeighborSampler(2 ) dataloader = dgl.dataloading.NodeDataLoader( g, train_nid_dict, sampler, batch_size=1024 , shuffle=True , drop_last=False , num_workers=4 )
模型的训练与同构图几乎相同。不同之处在于, compute_loss 的实现会包含两个字典:节点类型和预测结果 。
model = StochasticTwoLayerRGCN(in_features, hidden_features, out_features, etypes) model = model.cuda() opt = torch.optim.Adam(model.parameters()) for input_nodes, output_nodes, blocks in dataloader: blocks = [b.to(torch.device('cuda' )) for b in blocks] input_features = blocks[0 ].srcdata output_labels = blocks[-1 ].dstdata output_predictions = model(blocks, input_features) loss = compute_loss(output_labels, output_predictions) opt.zero_grad() loss.backward() opt.step()
DGL提供了端到端随机批次训练的 RGCN的实现 。
用户可以使用 和节点分类一样的邻居采样器 。
sampler = dgl.dataloading.MultiLayerFullNeighborSampler(2 )
想要用DGL提供的邻居采样器做边分类,需要将其与 EdgeDataLoaderEdgeDataLoaderblock。
例如,以下代码创建了一个PyTorch数据加载器,该PyTorch数据加载器以批的形式迭代训练边ID的数组 train_eids:
dataloader = dgl.dataloading.EdgeDataLoader( g, train_eids, sampler, batch_size=1024 , shuffle=True , drop_last=False , num_workers=4 )
用户在训练边分类模型时,有时希望从计算依赖中删除出现在训练数据中的边,就好像这些边根本不存在一样。 否则,模型将 “知道” 两个节点之间存在边的联系,并有可能利用这点 “作弊” 。
因此,在基于邻居采样的边分类中,用户有时会希望从采样得到的小批次图中删去部分边及其对应的反向边。 用户可以在实例化 EdgeDataLoaderexclude='reverse_id',同时将边ID映射到其反向边ID。 通常这样做会导致采样过程变慢很多,这是因为DGL要定位并删除包含在mini-batch中的反向边。
n_edges = g.number_of_edges() dataloader = dgl.dataloading.EdgeDataLoader( g, train_eid_dict, sampler, exclude='reverse_id' , reverse_eids=torch.cat([ torch.arange(n_edges // 2 , n_edges), torch.arange(0 , n_edges // 2 )]), batch_size=1024 , shuffle=True , drop_last=False , num_workers=4 )